21 Apr 🛡️ Disaster Recovery en AWS: Estrategias, Arquitecturas y Mejores Prácticas
🛡️ Disaster Recovery en AWS: Estrategias, Arquitecturas y Mejores Prácticas.
En entornos modernos en la nube, la disponibilidad no es opcional. Las organizaciones deben diseñar sistemas resilientes capaces de soportar fallas, interrupciones y eventos inesperados. Aquí es donde entra en juego el Disaster Recovery (DR) en AWS.
En este artículo exploramos las estrategias de recuperación ante desastres, cómo elegir la más adecuada y cómo implementarlas correctamente siguiendo el AWS Well-Architected Framework.
🚨 ¿Qué es Disaster Recovery?
Disaster Recovery (DR) es el conjunto de estrategias, políticas y herramientas que permiten recuperar sistemas, aplicaciones y datos tras un evento disruptivo.
AWS facilita esto mediante infraestructura global, servicios administrados y capacidades multi-región.
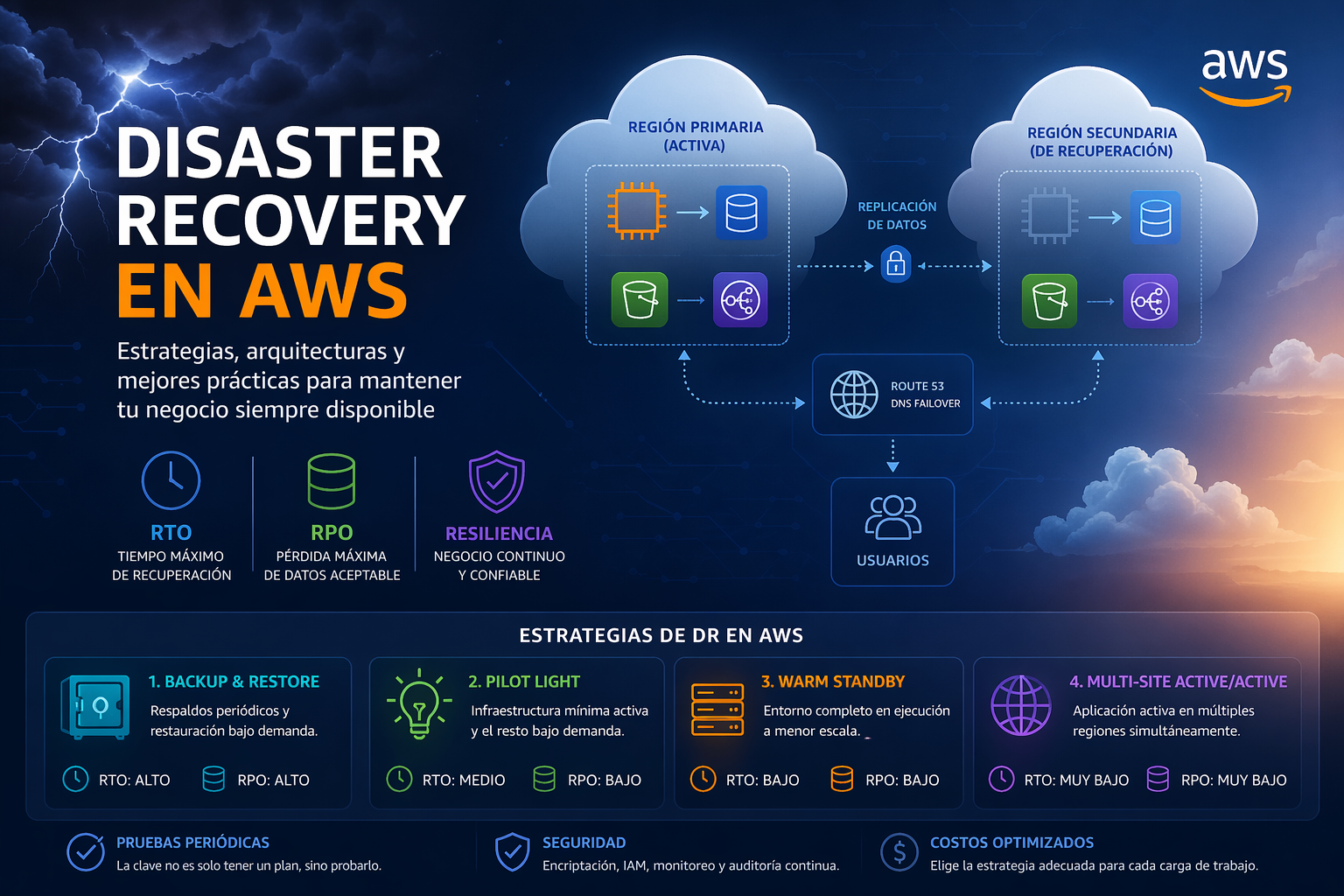
🎯 Conceptos clave: RTO y RPO
Antes de diseñar cualquier estrategia de DR, es fundamental entender:
- RTO (Recovery Time Objective): Tiempo máximo para recuperar el servicio.
- RPO (Recovery Point Objective): Cantidad máxima de datos que puedes perder.
👉 Ejemplo práctico:
- RTO = 1 hora → sistema disponible en máximo 1 hora
- RPO = 5 minutos → pérdida máxima de 5 minutos de datos
🧱 Estrategias de Disaster Recovery en AWS
AWS define 4 estrategias principales, cada una con un balance distinto entre costo, complejidad y rapidez de recuperación.
🟢 1. Backup & Restore (Bajo costo)
Descripción:
Se almacenan backups y se restauran en caso de desastre.
Ventajas:
- Muy económico
- Fácil de implementar
Desventajas:
- Alto tiempo de recuperación
- Posible pérdida de datos significativa
Ideal para:
- Sistemas no críticos
- Ambientes de testing o reporting
🟡 2. Pilot Light
Descripción:
Mantiene una versión mínima del sistema activa (principalmente datos).
Ventajas:
- Balance entre costo y recuperación
- Recuperación más rápida que backup tradicional
Desventajas:
- Requiere automatización para escalar
Ideal para:
- Aplicaciones importantes
- Sistemas con tolerancia moderada
🟠 3. Warm Standby
Descripción:
Sistema completo funcionando en una región secundaria a menor escala.
Ventajas:
- Baja latencia de recuperación
- Alta disponibilidad
Desventajas:
- Costos elevados
- Mayor complejidad operativa
Ideal para:
- Sistemas críticos de negocio
🔴 4. Multi-Site Active/Active
Descripción:
Aplicación activa en múltiples regiones simultáneamente.
Ventajas:
- Recuperación casi inmediata
- Alta resiliencia global
Desventajas:
- Muy costoso
- Complejidad alta (consistencia de datos)
Ideal para:
- Sistemas financieros, e-commerce global, salud
🧠 ¿Cómo elegir la mejor estrategia?
La clave está en alinear:
- Criticidad del sistema
- RTO/RPO definidos
- Presupuesto disponible
Ejemplo práctico:
| Tipo de sistema | Estrategia |
|---|---|
| Crítico | Warm Standby / Multi-Site |
| Importante | Pilot Light |
| No crítico | Backup & Restore |
⚙️ Buenas prácticas en AWS
🔐 Seguridad
- IAM con principio de mínimo privilegio
- Encriptación de datos (KMS)
- Auditoría con CloudTrail
💰 Costos
- Optimizar entornos standby con Auto Scaling
- Usar almacenamiento eficiente (S3 Glacier para backups)
📈 Escalabilidad
- Diseñar aplicaciones stateless
- Uso de servicios administrados (RDS, DynamoDB, S3)
🏁 Conclusión
No existe una estrategia única de Disaster Recovery. La clave es diseñar un enfoque híbrido basado en:
- Impacto del negocio
- Requerimientos de disponibilidad
- Capacidad financiera
AWS proporciona todas las herramientas necesarias para construir arquitecturas resilientes, pero el diseño correcto depende de decisiones bien fundamentadas.
💡 Tip final:
No basta con diseñar DR — debes probarlo regularmente.
Happy Hacking!
Fuentes Consultadas:
https://aws.amazon.com/es/what-is/disaster-recovery/
https://aws.amazon.com/es/blogs/aws-spanish/arquitectura-de-recuperacion-ante-desastres-en-aws-parte-1-estrategias-de-recuperacion-en-la-nube/
https://aws.amazon.com/es/disaster-recovery/
https://docs.aws.amazon.com/es_es/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html
https://docs.aws.amazon.com/es_es/prescriptive-guidance/latest/backup-recovery/disaster-recovery.html
https://dev.to/aws-builders/recuperacion-de-desastres-una-opcion-costo-efectiva-aws-elastic-disaster-recovery-n31
https://aws.amazon.com/es/blogs/aws-spanish/implementando-una-estrategia-de-recuperacion-de-desastres-con-amazon-rds/
https://medium.com/@eltechno/entendiendo-rto-y-rpo-en-la-recuperaci%C3%B3n-de-desastres-aws-18d5822cd3fd